Portfolio · 2026
I build things end-to-end and write about it.
CS at UT Austin. Researching inference systems with UTNS. Joining Anduril this summer. Trained GPT-2 from scratch on 4 A100s; writing about the stack as I learn it.

Now
Researching diffusion-model inference caching at UTNS.
Austin · TX
Selected work
 03/
LLM Stack from First Principles
Worked through Karpathy's Zero to Hero — autograd engine, MLP, batchnorm, WaveNet, char-level transformer, BPE, GPT-2. Wrote a technical blog covering each.
03/
LLM Stack from First Principles
Worked through Karpathy's Zero to Hero — autograd engine, MLP, batchnorm, WaveNet, char-level transformer, BPE, GPT-2. Wrote a technical blog covering each.
 04/
Cornucopia
AI-powered fridge inventory tracker that reduces food waste and suggests recipes from CV-detected items. 1st place + Best Use of GenAI at IEEE UT's 2025 Techathon.
04/
Cornucopia
AI-powered fridge inventory tracker that reduces food waste and suggests recipes from CV-detected items. 1st place + Best Use of GenAI at IEEE UT's 2025 Techathon.

05/
Lock-Free Web Server
Multithreaded lock-free web server in Rust.
 06/
Barnes-Hut N-Body
Efficient N-body simulation using the Barnes-Hut algorithm.
06/
Barnes-Hut N-Body
Efficient N-body simulation using the Barnes-Hut algorithm.
 07/
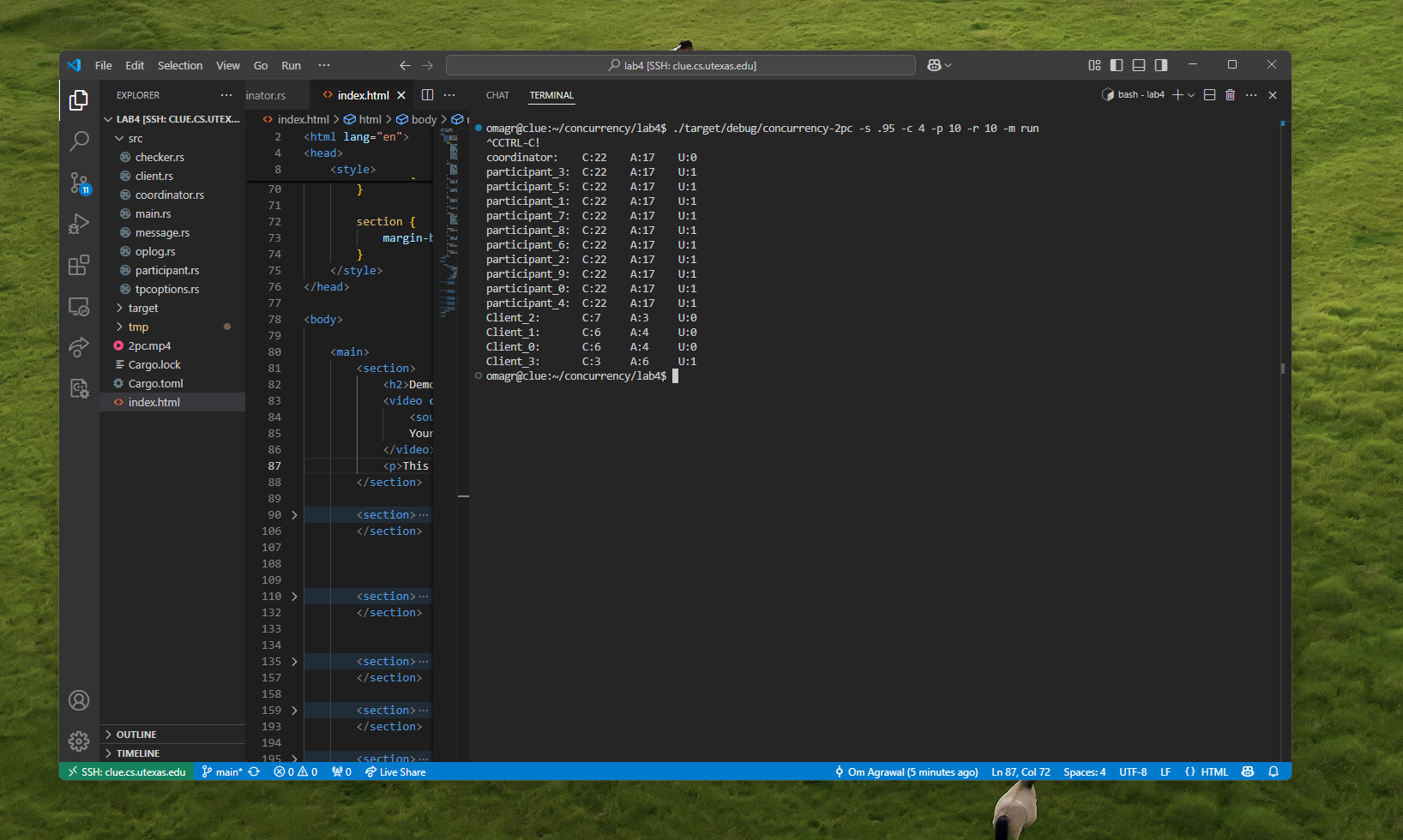
2-Phase Commit in Rust
A 2-phase commit protocol simulation in Rust.
07/
2-Phase Commit in Rust
A 2-phase commit protocol simulation in Rust.
 08/
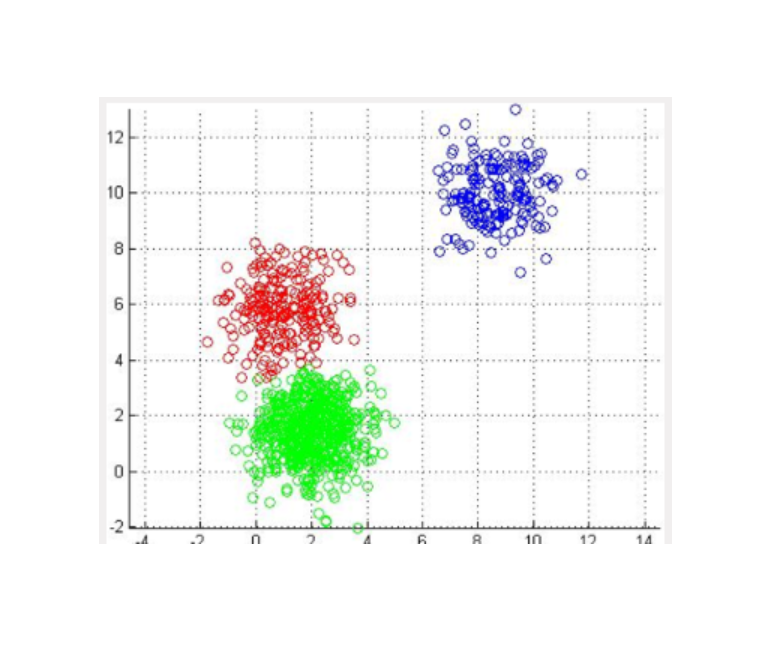
K-means on GPU
GPU-accelerated K-means clustering algorithm.
08/
K-means on GPU
GPU-accelerated K-means clustering algorithm.
 09/
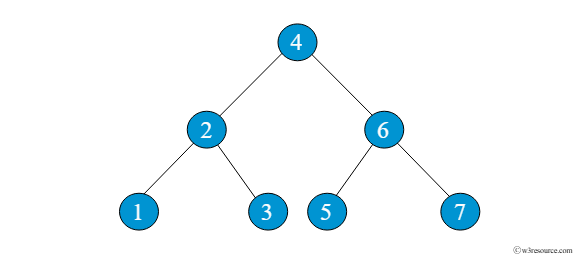
BST Lightning
High-performance multithreaded algorithm for identifying equivalent binary search trees.
09/
BST Lightning
High-performance multithreaded algorithm for identifying equivalent binary search trees.
 10/
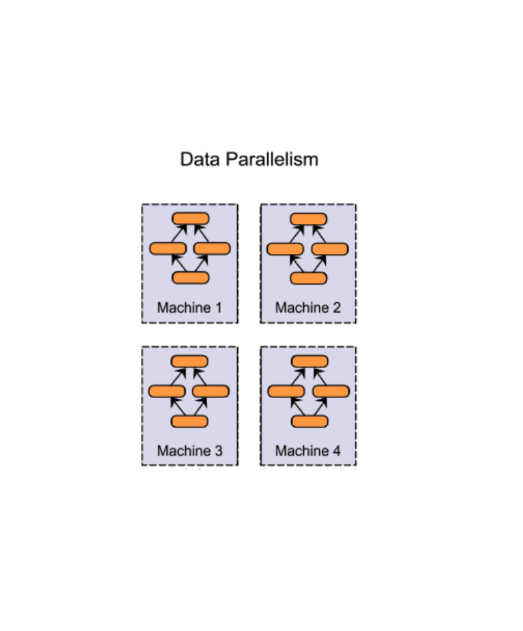
DDP Training
Distributed data-parallel training of VGG11 on CIFAR-10 with AWS SageMaker — scaling analysis of parallelism vs. gradient-sync overhead.
10/
DDP Training
Distributed data-parallel training of VGG11 on CIFAR-10 with AWS SageMaker — scaling analysis of parallelism vs. gradient-sync overhead.
 11/
LoRA Fine-Tuning
Parameter-efficient fine-tuning of TinyLlama with LoRA adapters in MLP layers — measured training latency vs. rank and module size.
11/
LoRA Fine-Tuning
Parameter-efficient fine-tuning of TinyLlama with LoRA adapters in MLP layers — measured training latency vs. rank and module size.
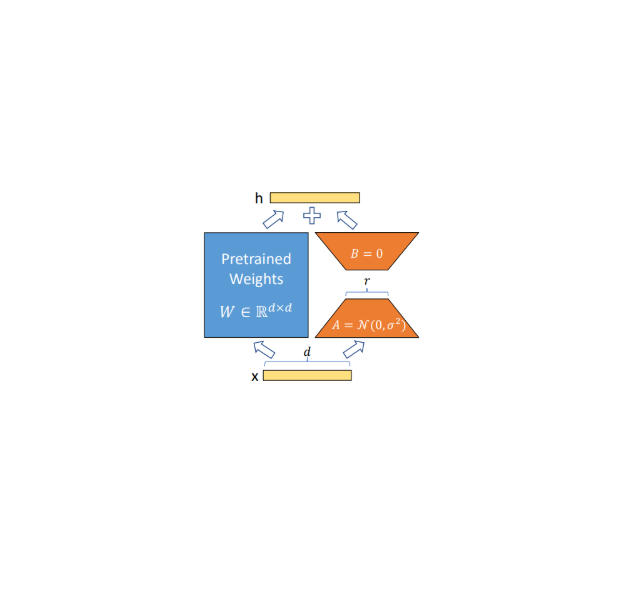 12/
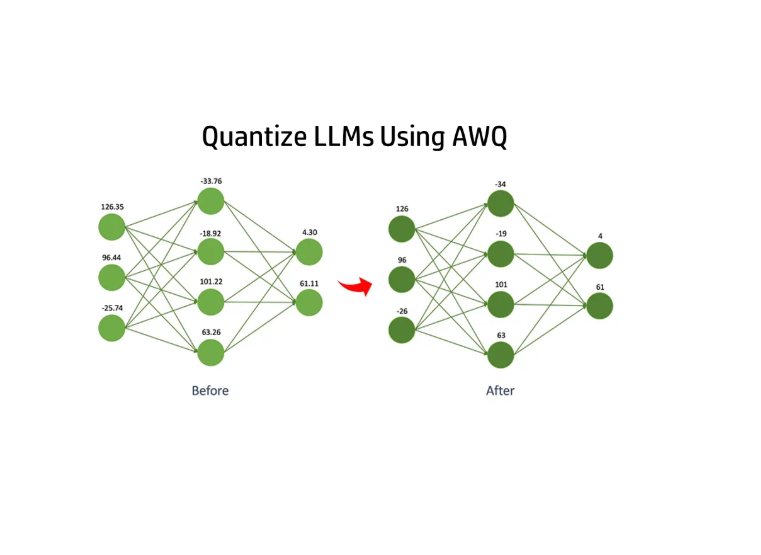
Activation-Aware Quantization
Quantized OPT-1.3B to 3 bits while protecting the top 1% of salient weights via hardware-friendly scaling.
12/
Activation-Aware Quantization
Quantized OPT-1.3B to 3 bits while protecting the top 1% of salient weights via hardware-friendly scaling.
 13/
Bhagavad-GPT
A RAG chatbot grounded in the Bhagavad Gita, referencing an authoritative knowledge base.
13/
Bhagavad-GPT
A RAG chatbot grounded in the Bhagavad Gita, referencing an authoritative knowledge base.
06/
Barnes-Hut N-Body
Efficient N-body simulation using the Barnes-Hut algorithm.
07/
2-Phase Commit in Rust
A 2-phase commit protocol simulation in Rust.
08/
K-means on GPU
GPU-accelerated K-means clustering algorithm.
09/
BST Lightning
High-performance multithreaded algorithm for identifying equivalent binary search trees.
10/
DDP Training
Distributed data-parallel training of VGG11 on CIFAR-10 with AWS SageMaker — scaling analysis of parallelism vs. gradient-sync overhead.
11/
LoRA Fine-Tuning
Parameter-efficient fine-tuning of TinyLlama with LoRA adapters in MLP layers — measured training latency vs. rank and module size.
12/
Activation-Aware Quantization
Quantized OPT-1.3B to 3 bits while protecting the top 1% of salient weights via hardware-friendly scaling.
13/
Bhagavad-GPT
A RAG chatbot grounded in the Bhagavad Gita, referencing an authoritative knowledge base.
Recent writing
Experience
Anduril
Software Engineering Intern
INCOMING
UT Networked Systems Research
Student Researcher
Designing a caching mechanism to speed up inference for video-generation diffusion models, with postdoc Saurabh Agarwal and Prof. Aditya Akella.
ForeFlight
Software Engineering Intern
Built a multithreaded Rust UDP client to unify networking across ~50 hardware devices, replacing disparate protocols with a single scalable solution.
Federal Aviation Administration
Intern, Office of Senior Technical Experts
Built an algorithm over 50M ADS-B datapoints to detect aircraft GPS "jumps"; shipped a flight-track viewer in Kepler.gl + Streamlit.
UT Austin CS
Course Assistant — Discrete Mathematics
Led discussion sections on prop logic, proof techniques, graph theory, asymptotics.